Datos desde IRIS a Google Big Query - InterSystems Cloud SQL mediante Dataflow
 | Cómo incluir IRIS Data en vuestro almacén de datos de Google Big Query y en vuestras exploraciones de datos de Data Studio. En este artículo utilizaremos Google Cloud Dataflow para conectarnos a nuestro Servicio de InterSystems Cloud SQL y crear un trabajo para persistir los resultados de una consulta de IRIS en Big Query en un intervalo. Si tuvisteis la suerte de obtener acceso a Cloud SQL en el Global Summit 2022, como se menciona en "InterSystems IRIS: What's New, What's Next" (InterSystems IRIS: Lo nuevo, lo siguiente), el ejemplo será pan comido, pero se puede realizar con cualquier punto de acceso público o vpc que hayáis provisionado. |

Al examinar vuestra implementación, podéis dirigiros al panel "External Connections" (Conexiones externas) en la pestaña "Overview" y crear vosotros mismos una URL de conexión y conservar vuestras credenciales. Optamos por permitir acceso público (0.0.0.0/0) al punto de conexión y no cifrarlo.

Desde arriba, tendréis que difundir la siguiente información...
ConnectionURL:
jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USERUser/Pass:
SQLAdmin/Testing12!DriverClassName:
com.intersystems.jdbc.IRISDriver- Provisionar un proyecto GCP
gcloud projects create iris-2-datastudio --set-as-default
- Habilitar Big Query
- Habilitar DataFlow
- Habilitar el almacenamiento en la nube
gcloud services enable bigquery.googleapis.com gcloud services enable dataflow.googleapis.com gcloud services enable storage.googleapis.com
- Crear un cubo de almacenamiento en la nube
gsutil mb gs://iris-2-datastudio
- Subir el último controlador de conexión a la raíz del cubo.
wget https://github.com/intersystems-community/iris-driver-distribution/raw/main/intersystems-jdbc-3.3.0.jar gsutil cp intersystems-jdbc-3.3.0.jar gs://iris-2-datastudio
- Crear un conjunto de datos o DataSet de Big Query
bq --location=us mk \ --dataset \ --description "sqlaas to big query" \ iris-2-datastudio:irisdata
- Crear una tabla de destino en Big Query
Aquí es donde una ventaja súper potente se convierte en algo molesto para nosotros. Big Query puede crear tablas en tiempo real si se le suministra un esquema junto con una carga útil. Esto es genial dentro de pipelines y soluciones pero, en nuestro caso, necesitamos establecer la tabla con antelación. El proceso es sencillo, ya que se puede exportar un archivo CSV desde la base de datos IRIS con bastante facilidad con herramientas como DBeaver etc. y, cuando se tenga, se puede invocar el diálogo "Create table" (crear tabla) debajo del conjunto de datos que se creó y utilizar el archivo CSV para crear la tabla. Hay que asegurarse de tener marcada la opción "auto generate schema" ("autogenerar esquema") en la parte inferior del cuadro de diálogo.  Esto debería completar la configuración de Google Cloud, y deberíamos estar listos para configurar y ejecutar nuestro trabajo Dataflow.
Esto debería completar la configuración de Google Cloud, y deberíamos estar listos para configurar y ejecutar nuestro trabajo Dataflow.
Google Dataflow Job
Si seguisteis los pasos anteriores, deberíais tener lo siguiente en vuestro inventario para ejecutar el trabajo para leer vuestros datos de InterSystems IRIS e ingerirlos en Google Big Query utilizando Google Dataflow.
En Google Cloud Console, id a Dataflow y seleccionad "Create Job from Template" (Crear trabajo a partir de plantilla)

Esta es una imagen bastante innecesaria sobre cómo rellenar un formulario con los requisitos previos generados, pero destaca la fuente de los componentes...!
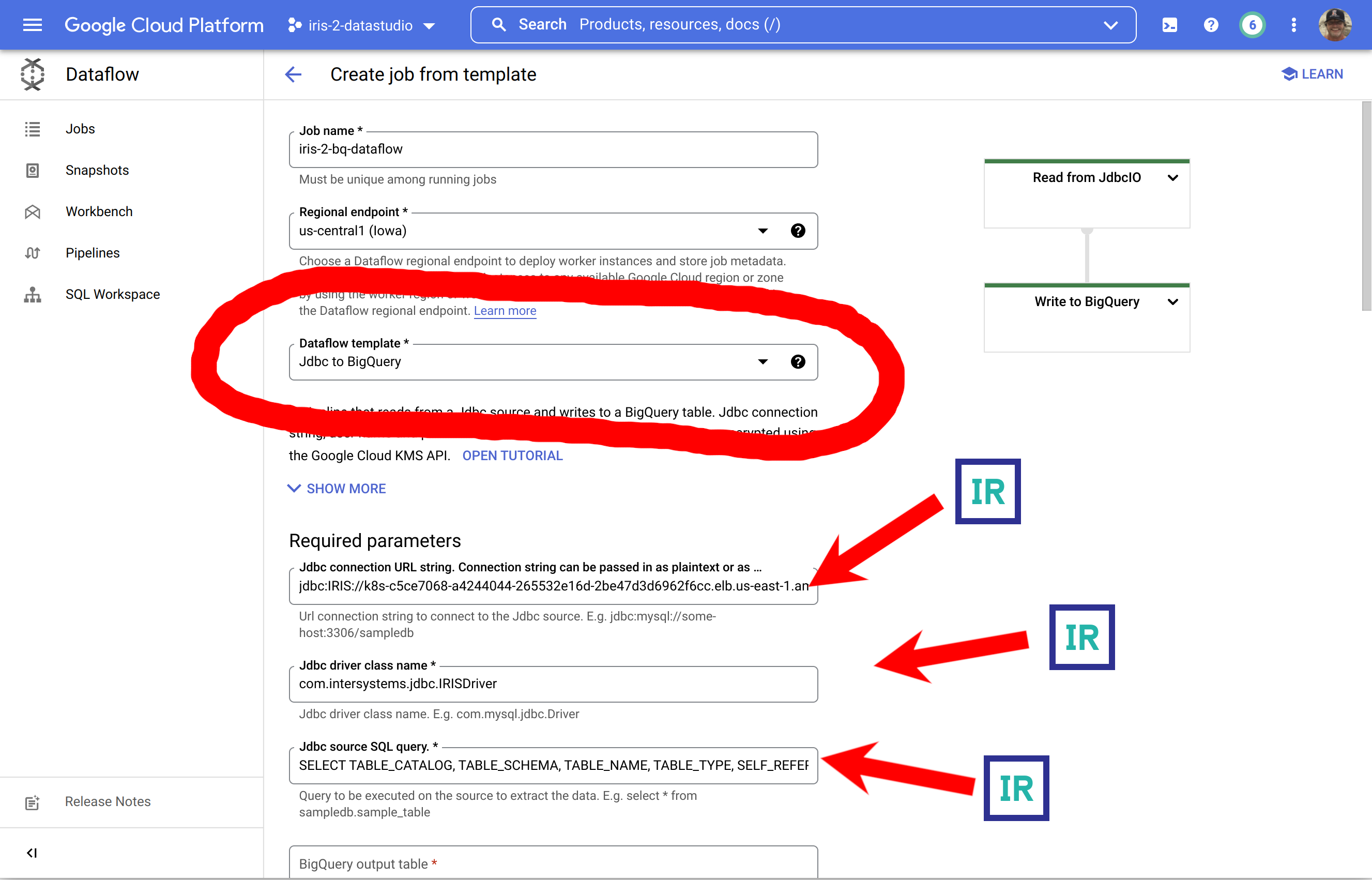
... para completarlo, aseguraos de expandir la sección inferior y facilitar vuestras credenciales para IRIS.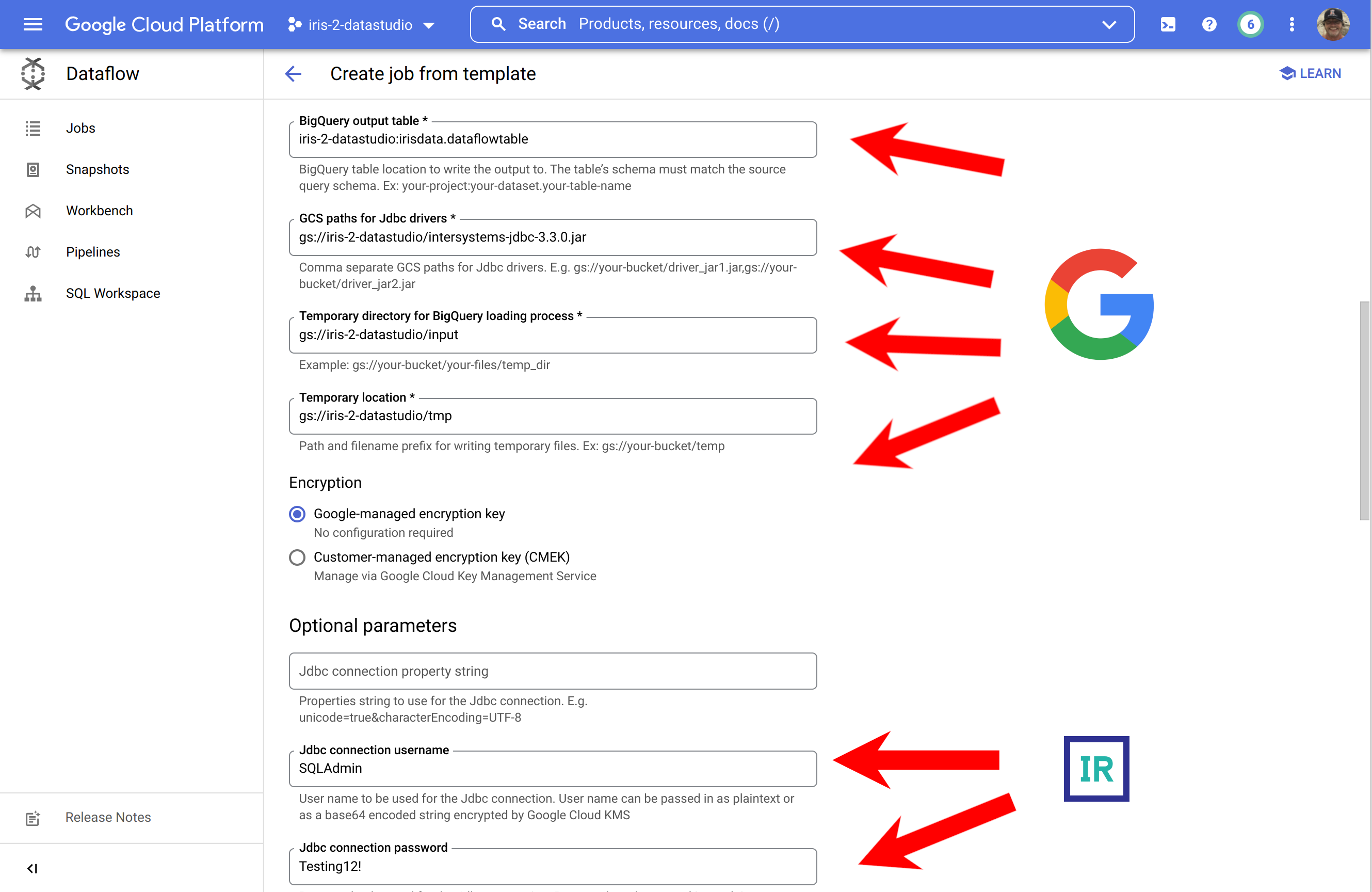
Para los que encontrasteis esas capturas de pantalla ofensivas a vuestra inteligencia, esta es la ruta alternativa a seguir para manteneros en vuestra zona de confort en la CLI para ejecutar el trabajo:
gcloud dataflow jobs run iris-2-bq-dataflow \ --gcs-location gs://dataflow-templates-us-central1/latest/Jdbc_to_BigQuery \ --region us-central1 --num-workers 2 \ --staging-location gs://iris-2-datastudio/tmp \ --parameters connectionURL=jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USER,driverClassName=com.intersystems.jdbc.IRISDriver,query=SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, TABLE_TYPE, SELF_REFERENCING_COLUMN_NAME, REFERENCE_GENERATION, USER_DEFINED_TYPE_CATALOG, USER_DEFINED_TYPE_SCHEMA, USER_DEFINED_TYPE_NAME, IS_INSERTABLE_INTO, IS_TYPED, CLASSNAME, DESCRIPTION, OWNER, IS_SHARDED FROM INFORMATION_SCHEMA.TABLES;,outputTable=iris-2-datastudio:irisdata.dataflowtable,driverJars=gs://iris-2-datastudio/intersystems-jdbc-3.3.0.jar,bigQueryLoadingTemporaryDirectory=gs://iris-2-datastudio/input,username=SQLAdmin,password=Testing12!
Una vez que hayáis iniciado vuestra tarea, podéis disfrutar de la gloria de un trabajo bien hecho:

Resultados
Echemos un vistazo a nuestros datos de origen y a la consulta en InterSystems Cloud SQL...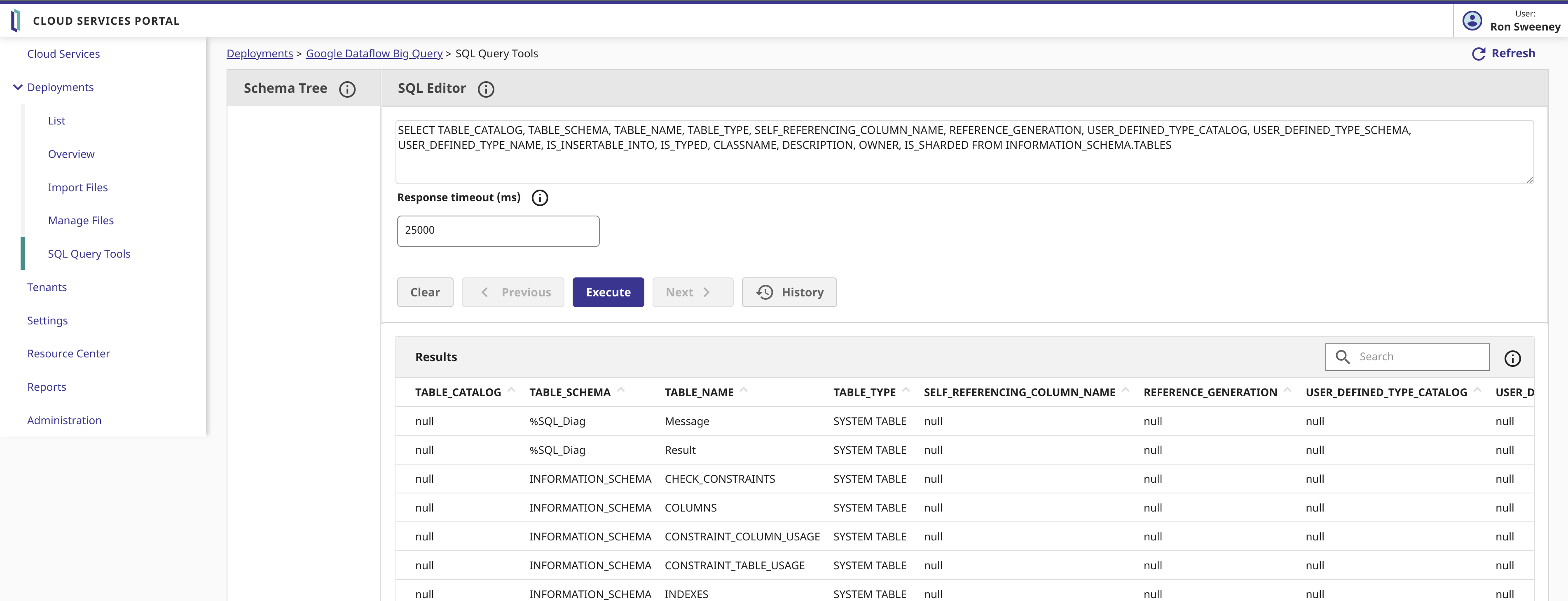
...y, después, examinando los resultados en Big Query, parece que, de hecho, tenemos InterSystems IRIS Data en Big Query.
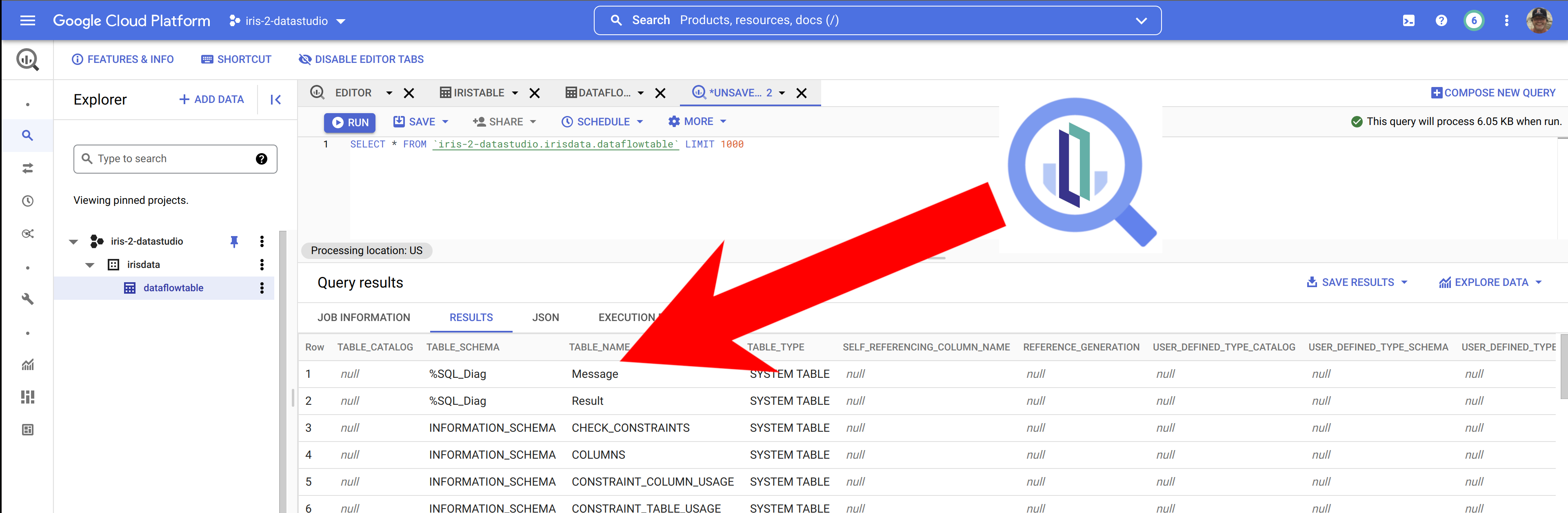
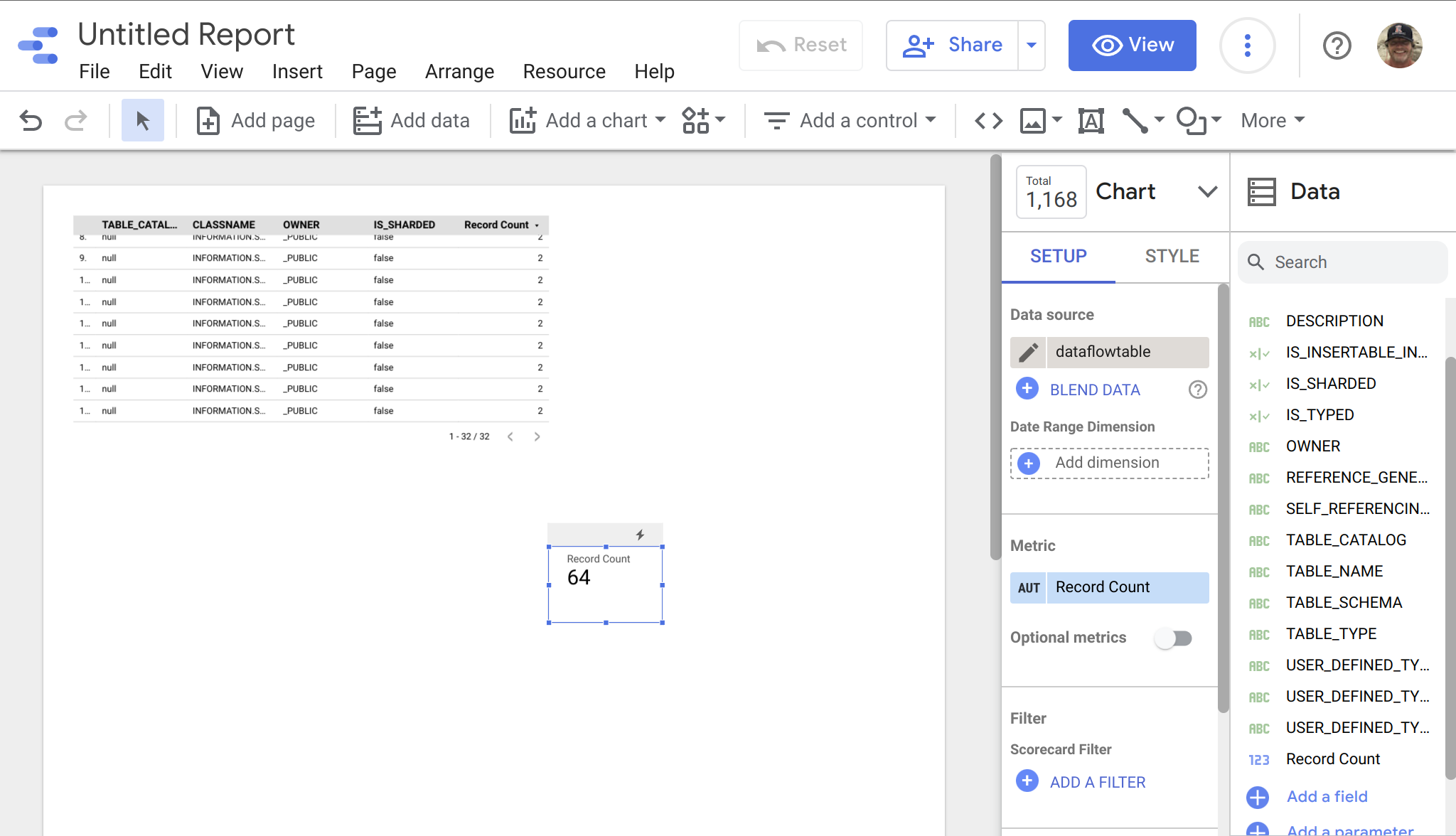
Cuando tengamos los datos en Big Query, es sencillo incluir nuestros datos de IRIS en Data Studio, seleccionando Big Query como fuente de datos... a este ejemplo de abajo le falta algo de estilo, pero se pueden ver rápidamente los datos de IRIS listos para su manipulación en vuestros proyectos en Data Studio.